I had an opportunity to work on an mobile application built on cordova. My hackathon project was about building a Notification Service and in order to integrate it to various channels, one of them being Mobile app, I worked on adding push plugin to the cordova app. For those who are new to cordova, it is "code in one language and deploy in many platforms" i.e. Platform independent. My JavaScript knowledge ranges from zero to none. But lucky for me, this change didn't involve much of JavaScript.
There were a few interesting review on exposing "too"much information on the notification payload. What is too much information depends on your business platform. So our initial thoughts of adding action buttons to the notification and hooking url to the action button on callbacks were all discarded due to the security risks. What I am going to outline here, is
- To get started with Cordova
- To send a push notification from FCM - Firebase Cloud Messaging and
- Receive it via Cordova Push Plugin
Installation
Follow the installation steps in the official Cordova documentation
here
- Install Node.js
- Ìnstall GIT
- Install Cordova - (I have tried the entire setup on windows)
Create a sample application
Since we are only going to try push notification, we don't need any fancy application here.
cordova create hello com.example.hello HelloWorld
Push plugin
does not work in browser platform, So lets directly add android platform.
cd hello/
cordova platform add android
You can check the
prerequisite for the building the platform.
cordova requirements
You would have to install Android SDK if you have not already. Follow
this documentation. You would have to add java home, android home and path variables (both platform tools and tools folders)
export ANDROID_HOME=~/Android/Sdk
export PATH=$PATH:~/npm-global/bin
export PATH=$PATH:$ANDROID_HOME/platform-tools:$ANDROID_HOME/tools
While installing Android SDK, if you face the issue where the gradle is not found under tools table.
http://stackoverflow.com/a/43027871 just download the tools lib and paste it in the location
And while installing emulator make sure the image has Google Play Service - any image greater than 4.2 is supposed to have Google Play Service
To check if your setup is fine, build and run it in emulator.
cordova build
cordova run --emulator
Make sure your emulator is running before issuing the command. Boot up the "Hello World" application in the emulator app screen.
How does Push Notification work?
I cannot explain it better than
this. Briefly,
There are Push Notification Providers such as FCM - Firebase Cloud Messaging (previously GCM - Google Cloud Messaging) APNS - Apple Push Notification Service
For these providers to send notification to your devices,
- Your device should register to providers. This will give your device an unique device registration key.
- This registration key is sent to the server
- Server asks the Notification Provider to send message to this registration key
This concept will be clear by the end of this post.
Setting up FCM
From this step you will need
- Sender ID
- Server Key
- Go to FCM
- Go to Project settings

- Navigate to Cloud Messaging tab

GCM has been migrated to FCM. now if you already have your project setup done at GCM and the API key is already generated, then this setup will work just fine (Google has provided backward compatibility) But if you have not setup API Key yet, then
you would have to migrate to FCM. Note that the Legacy Server Key in the screenshot is the one generated in GCM.
Sender ID in FCM is equivalent to the Project Number in GCM
Server Key in FCM is equivalent to the API Key in GCM
Let me briefly explain how the setup is in GCM. You can totally skip it if you are starting new with FCM
- Go to GCM
- Project Number, the one followed by # is your sender ID

- API Key - created specifically for GCM, is your Server Key. Navigate to API Manager
Navigate to the Credentials in Left Panel. That API Key is your server key
At this point you should have Sender ID and Registration Key
Setting up Push Plugin in the Cordova App
cordova plugin add phonegap-plugin-push --variable SENDER_ID="SENDER_ID_HERE"
Navigate to hello/www/index.js
var app = {
// Application Constructor
initialize: function() {
console.log("device readyState")
document.addEventListener("deviceready", this.onDeviceReady, false);
},
onDeviceReady: function() {
var push = PushNotification.init({ "android": {"senderID": "88338672842"},
"browser": {
"pushServiceURL": 'https://push.api.phonegap.com/v1/push'
},
"ios": {"alert": "true", "badge": "true", "sound": "true"}, "windows": {} }
);
push.on('registration', function(data) {
console.log("registration:");
console.log(data.registrationId);
});
push.on('notification', function(data) {
//console.log(data.title);
console.log(data.message);
// data.message,
// data.title,
// data.count,
// data.sound,
// data.image,
// data.additionalData
});
push.on('error', function(e) {
console.log("error");
console.log(e.message);
});
},
};
app.initialize();
During the application initialization, we are hooking the registration callback to deviceReady event.
Ideally you will send the registration Id to your server (to registration your user login with the registration key, which will be used further for sending push notification via providers by the server)
And then there is a notification callback - what should I do when the user taps on the notification or if the notification is received when the application is foreground. And there is an error handling callback as well.
Now rebuild the application.
cordova build android
cordova emulate android
Note that your emulator should already be running (Android SDK -> Tools -> Android -> AVD Manager). Navigate to the Hello World app.
We need the registration key that I printed in the registration callback.
How to view the console log statements?
Navigate to your android_home/platform-tools.
adb logcat browser:V
Sending Push Notification
Now that we have the registration key, all we need to send message to this key. You can do it via python like detailed
here
Or you can use a restful client and use the API
here
I used PostMan
- Add headers
- Authorization is the sender id (format : key=sender_id)
- set content-type to JSON
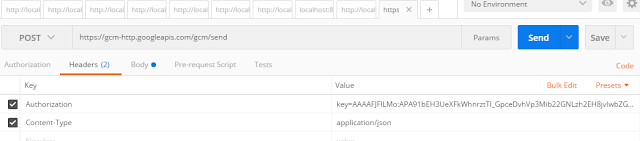
- Send the request body
- To - the registration key you got from the app

You will receive notification like:
you can check the console for the on Notification callback when you receive the notification while the app is on foreground

If you want the callback to work on the message tap, you need to set "content-available" in the notification payload.
And there are many more things to work on - logo, sounds, message stacking, etc. I would highly recommend you to go through
this documentation and decide what you want.
And note that you might have to do a lot of special handling depending on the device on which the app is installed - Android/IOS. You can make use of the
device plugin to determine the the device type and also send this information to the server when you are registering the device key. This will help the server send different payload (as per android/ios) when they are using the provider to send push notifications.
Also, as the documentation mentions, you might notice there are double events when the content-available is set to 1.
This post talks in detail about how to avoid that. Highlighting one particular comment.
if (data.additionalData.foreground) {
/**
* This block is reached when a push notification is received when the app is in foreground.
* Depending on the design of your app, you might want to save the incoming data to the localstorage here.
* That's not really what your question is about, but I thought mentioning it would give a better picture.
*/
}
else {
if (data.additionalData.coldstart) {
/**
* This block is reached when a push notification is tapped on *AND*
* the app is closed (ie. Not even in background).
*/
}
else {
/**
* The following block is reached in the following two scenarios:
* 1. A push notification is tapped on *AND* the app is in background.
* 2. A push notification with "content-available=1" is received while the app is in background. (iOS only)
*
* Therefore, for iOS devices, both of the above two scenarios can occur for an individual push notification.
*
* For Android, it's always the first scenario as the other one is not applicable.
*/
// Here we check for the existence of the incoming data in the localstorage and, with that, we determine
// which scenario of the two possible is happening.
var pastPushSavedID = window.localStorage.getItem("pastPushSavedID");
if (pastPushSavedID) {
// `pastPushSavedID` is found in localStorage and thus this is scenario 1 mentioned above.
}
else {
// `pastPushSavedID` is `null` and thus this is scenario 2 mentioned above.
}
}
}
A little bonus point. Try playing around with notification callback when
- app is foreground
- app is in background and running
- app is shut
Note that in all of these cases you are sending payload with content-available set
When I tried the callback worked for
- foreground
- app is shut (coldstart set to true)
But did not work for
- app is background and running
I found out
I was not the only one. But I still do not have a solution for this. Post on the comments if you face this as well.












